
ABBYY FineReader 11是一款专业图片文字识别软件,它通过扫描纸质文档、PDF和数字照片创建可编辑的、可搜索的文件和电子书。世界各地2000多万人在家中和办公室使用ABBYYFineReader进行文本识别和文档处理。ABBYY FineReader 11速度和准确性的新水平分享了无与伦比的识别和转换,几乎消除了重新键入或重新格式化。
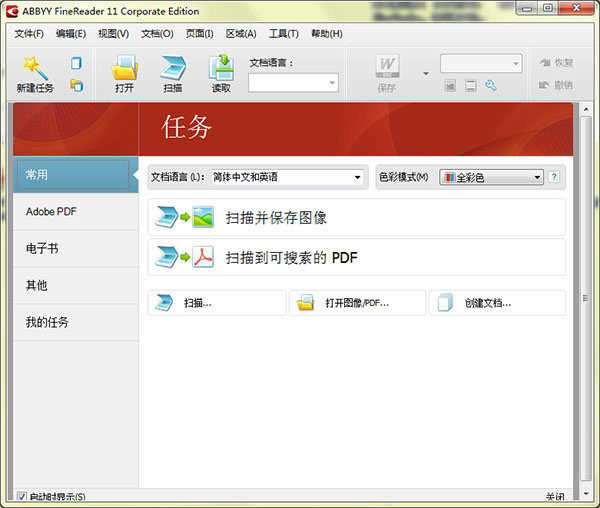
ABBYY FineReader 11特色介绍
提升处理效率
使用全新的黑白模式,当您不需要彩色时,ABBYY FineReader 11分享的处理速度提高 30%。此外,该程序有效利用了多核处理器的优势,使转换速度更快。
OpenOffice支持
ABBYY FineReader 11将文档和 PDF 文件的图像直接识别和转换为 OpenOffice Writer 格式(ODT),准确保留它们的本机布局及格式。您只需点击几次鼠标就可以轻松地将文档添加到您的 *.odt 档案。
增强用户界面
ABBYY FineReader 11 分享了一套强大的的新图像编辑工具,包括亮度和对比度滑块以及水平工具,确保您能获得更准确的结果并提高图像参数。
OCR 准确度
ABBYY FineReader可更好地检测文档样式、脚注、页眉、页脚和图片标题,大程度地减少编辑已转换文档所需的时间。
优化PDF 输出
PDF 文件的三个预定义的图像设置根据您的需求分享了优化的结果 – 好的质量、压缩大小或平衡模式
支持名片输入
ABBYY FineReader使用名片阅读器,快速将纸质名片转换为电子联系人(仅 Corporate Edition 分享此功能)
ABBYY FineReader 11功能
1、提升处理效率
通过使用全新的黑白模式,当您不需要彩色时,FineReader 11 分享的处理速度提高 30%。此外,该程序有效利用了多核处理器的优势,使转换速度更快。
2、创建电子书灵活多变
扫描纸质书并将它们转换为 ePub 和 fb2 格式,以便在路途上用您的 iPad、平板电脑或最喜欢的便携设备进行阅读。或者,直接将它们发送至您的 Kindle 帐户。将纸质书或文章转换为相应的电子书格式,以便将它们添加到您的电子图书馆或档案中。
3、对OpenOffice.org Writer的本机支持
FineReader 11 将文档和 PDF 文件的图像直接识别和转换为 OpenOffice.org Writer 格式 (ODT),准确保留它们的本机布局及格式。现在,您只需点击几次鼠标就可以轻松地将文档添加到您的 *.odt 档案。
4、增强用户界面
●增强的样式编辑器允许您在一个界面友好的窗口中设置所有样式参数。所有的更改会立即应用于整个文档。
●在 FineReader 文档中组织页面,从而获取更佳的布局保留。
●当程序启动后,立即启动文档转换,就可以更容易访问所有基本或高级转换任务。
5、配备有强大的图像编辑工具扩充组的下一代相机 OCR
FineReader 11 分享了许多强大的的新图像编辑工具,包括亮度和对比度滑块以及水平工具,确保您通过改进图像质量来获得更准确的结果。
6、通过改进型 ADRT 2.0 增强了 OCR 准确度及布局保留
由于可更好地检测文档样式、脚注、页眉、页脚和图片标题,最大程度地减少编辑已转换文档所需的时间。
7、优化的PDF输出
PDF文件的三个预定义的图像设置根据您的需求分享了优化的结果 – 最好的质量、压缩大小或平衡模式。
8、新识别语言阿拉伯语、越南语和土库曼语(拉丁字母 )。
使用名片阅读器,快速将纸质名片转换为电子联系人(仅 Corporate Edition 分享此功能)
ABBYY FineReader 11破解安装教程
1、下载数据包然后解压。双击“ABBYY_FineReader_11_CE.exe”选择点击“单独安装”,默认选择简体中文然后一直点击下一步直至安装结束即可
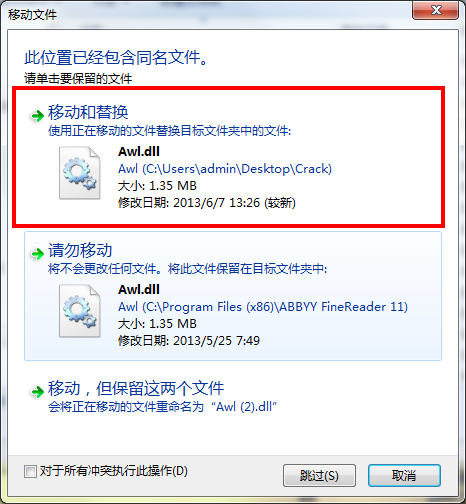
2、安装完成后,将“Crack”目录下的补丁“Del_Lic_Ser.exe”和“Awl.dll”复制到安装目录下覆盖源文件即可,默认安装目录为C:Program Files (x86)ABBYY FineReader 11
ABBYY FineReader 11使用教程
把PDF转成可编辑文件
首先知识兔要做的就是打开一个需要转换的PDF文件,然后看一下这个文件里面有几种语言,是不是有表格、图片等
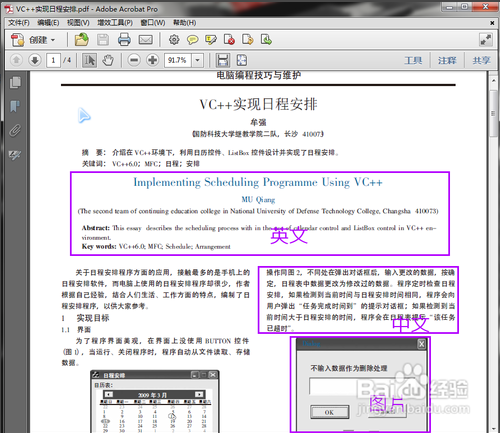
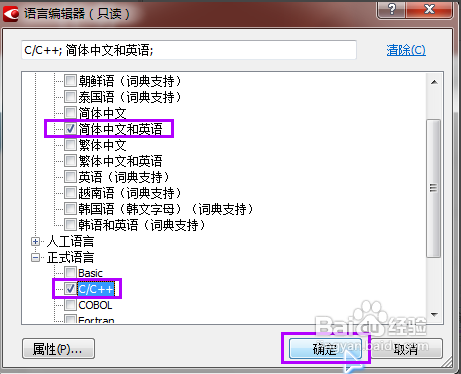
然后运行ABBYY finereader 11,点击欢迎界面“文档语言”下拉选择中的更多语言,弹出“语言编辑器”界面,知识兔设置好PDF文件中所包含的几种语言。
因为文件文件中有C++语言的内容,而ABBYY finereader 中正好也有C++的选择,那么知识兔就毫不犹豫的打上勾。设置完毕,点击右下角的“确定”按键。
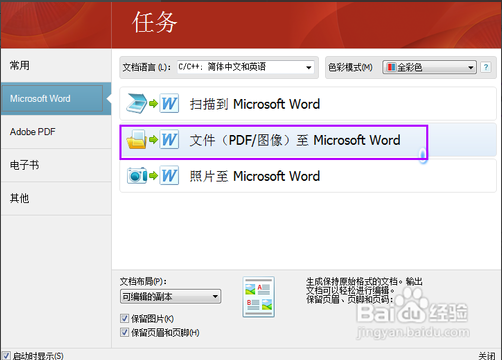
回到任务界面,知识兔是想把PDF转成可编辑的word文件,所以知识兔点击中间的“文件(PDF/图片)到Microsoft Word”一项
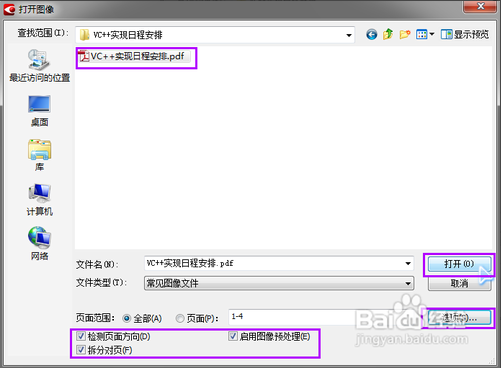
弹出文件选择窗口,选择需要转换的PDF文件,注意打开窗口的左下角那几个选项,默认都是打勾的,如果不需要的话可以去掉勾,然后点击“打开”按键。
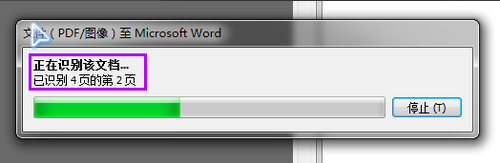
ABBYY finereader开始加载文件,并且自动OCR识别处理。如果页数比较多的话,可能需要花费一些时间,需要耐心等待一下。
由于自动识别会有一些错误,那么我就可以用手动工具进行修正。知识兔可以选择不同的工具来修正,比如表格被识别成了普通文字,中间没有线框了,那么知识兔选择“表格”工具,然后把文件中的表格的区域选出来,然后右键“读取区域”就能够手动识别成表格了。还有如果带有文字的图片被自动识别成了文字了,那么知识兔可以选择图片工具选出页面中的图片区域,然后在你识别本页面其他部分文字的时候,这个区域就会被识别成图片了。
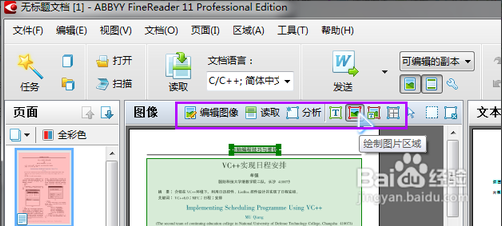
“编辑图像”按键是用来预处理扫描页图片的,因为扫描页有时候会有倾斜、对比度不好、变形等问题,那么先对图像修正一下可以大幅度提高识别的准确率,调整完以后点击右上角的“退出图像编辑器”按键就可以回到上一界面。
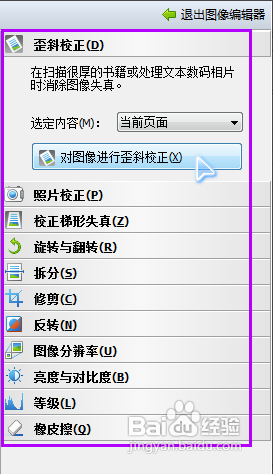
识别完毕以后,选择菜单来的“文件”---“将文档另存为”---“Microsoft Word文档”(如果你需要保存为其他格式你可以自己选择)。
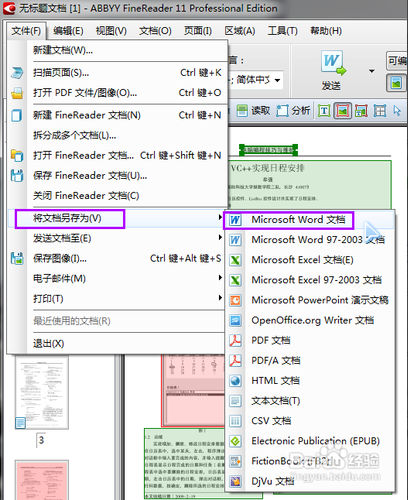
弹出保存对话框,选择保存路径,如果需要保存完就打开文件的话,记得勾选下面的“保存后打开文档”选项,如果电脑配置不高的话不建议勾选此项,因为ABBYY finereader本身比较耗内存,然后再打开word的话电脑可能会比较卡。保存完文件,转换过程就基本结束了。
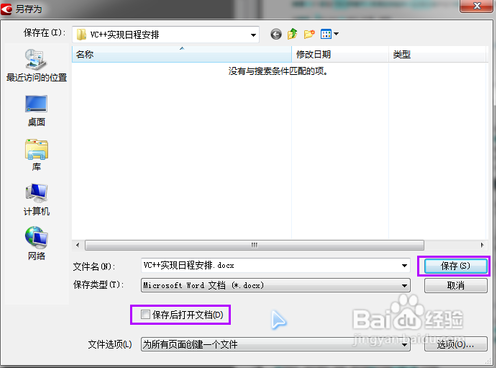
知识兔打开保存好的word文件,看看转换的效果怎么样。识别的区域基本上正常,中文英文、图像都可以识别出来,版面略微有些错位,不过还是含有部分错误,知识兔需要自己修改一下,但是这个已经可以大大降低知识兔的录入强度了。

ABBYY FineReader 11常见问题
1、ABBYY_FineReader 11菜单栏全是英文的怎么改成中文的?
ABBYY FineReader 设置里面有“语言切换”,依次点开菜单tools-options-advanced-other下面的interface language改成中文即可。
2、ABBYY finereader 11怎么合并拆分的pdf??
取消ABBYY FineReader中“拆分对页”的设置后再试试。
依次点击abbyy finereader工具栏上的工具→选项→扫描/打开→图像预处理→一般修复→拆分对页。
3、abbyy finereader 11 简体中文版安装之后出现这种情况 怎么解决?
在 abbyy finereader 11 安装目录下找到 “ FineReader.exe ”文件,并以管理员身份运行这个文件,打开软件,同时给这个文件创建快捷方式放在桌面,下次双击快捷方式可以打开软件。
4、abbyy finereader 11与相机怎么配合?
用相机拍摄所需要转换的图片,拍摄时保证所拍摄书籍或者杂志平整。
打开ABBYY软件,载入所拍摄图片,就能自动转换成文本文档,可保存成word等格式。
特别适合写论文,图书馆翻拍书籍用。
下载仅供下载体验和测试学习,不得商用和正当使用。
下载体验