
超强ORC识别软件是一款专业的文字识别软件。ORC识别软件是指将扫描图上的文字识别并提取出来的软件,这款超强ORC识别软件也可以自动解析图文内容,一键转换保存文本,文字识别准确率高达99%,有效提高了一些用户的文字录入速度。
超强ORC识别软件功能
【精准识别文字信息】
软件采用先进的OCR识别技术,高达99%的识别精度,轻松实现文档数字化。
【完美还原文档格式】
软件可一键读取文档,完美还原文档的逻辑结构和格式,无需重新录入和排版。
【自动解析图文版面】
软件对图文混排的文档具有自动分析功能,将文字区域划分出来后自动进行识别。
【极速识别文本内容】
软件具备高智能化识别内核,通过智能简化软件使用的操作步骤,实现极速识别。
【强大识别纠错技术】
软件分享更强大的文字识别纠错技术,精准地检测出文档样式、标题等内容。
【改进图片处理算法】
软件进一步改进图像处理算法,提高扫描文档显示质量,更好地识别拍摄文本。
超强ORC识别软件使用教程
步骤一:首先打开需要转换的图像或PDF文件,看一下有哪些语言文字;
步骤二:运行“超强OCR文字识别软件”,在“文档语言”下拉列表中选择“更多语言”;
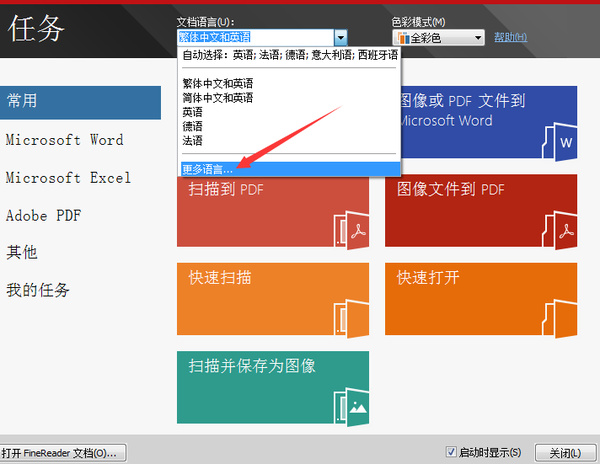
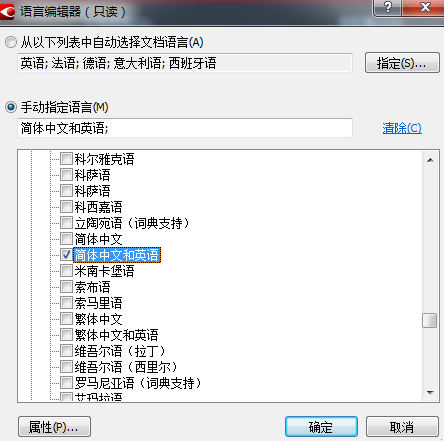
步骤三:在“语言编辑器”中勾选包含的语言“简体中文和英语”,点击“确定”;
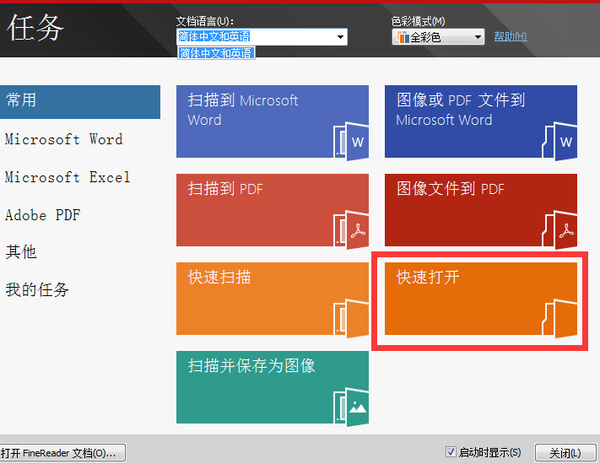
步骤四:返回“任务”,点击“快速打开”;
步骤五:弹出“打开图像”对话框,选择需要转换的文件,也可以选择多个文件批量识别转换,例如选择PDF文件,勾选自定义页面范围,输入“5-8”页面识别,然后点击“打开”;
步骤六:在“主工具栏”上点击“读取”,读取所有的未识别的页面;
步骤七:”超强OCR文字识别软件“将自动分析页面不同类型的区域,如文本、图片、背景图片、表格和条形码,在“图像”窗口绘制和调整未能正确识别的检测区域,调整区域之后请再次点击“读取”以识别;
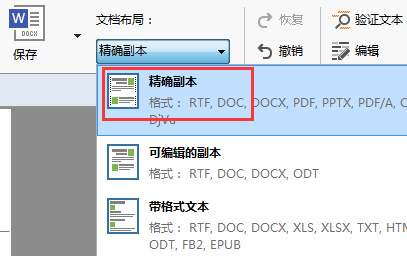
步骤八:如果“文本”窗口识别版面和源文件版面相差太大,在“主工具栏”将“文档布局”选择为“精确副本”;一般推荐“可编辑的副本”
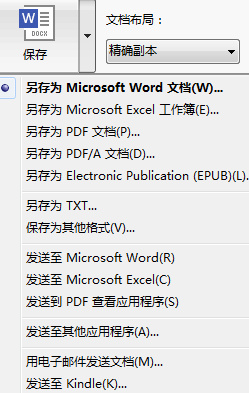
步骤九:在“文本”窗口会将可能错误的字符以蓝色背景颜色显示出来,便于校对更正,可以右键文字以显示原图像和待选字符,再选择正确字符,对没有正确识别字符直接手动输入更正;
步骤十:校对完成之后,在“主工具栏”上选择“另存为Microsoft Word文档”,或选择菜单“文件”-“将文档另存为”-“Microsoft Word文档”,也可以保存为其他可编辑的格式。
注:有些文件比较模糊,可以按下图尝试调整分辨率。一般300dpi,其他分辨率可以根据文件多尝试。别忘了点击应用,退出图像编辑器。退出后重新点击读取页面
超强ORC识别软件注意事项
转换中有些格式不正确,需要自己根据原来的格式调整一下。
有些特殊的字体,该软件无法识别需要手动修改一下。
超强ORC识别软件更新日志
1、优化了图片文字识别的速度。
2、软件安装支持中英2种语言。
3、提升pdf文件的识别转换效果。
4、提升软件的稳定性。
下载仅供下载体验和测试学习,不得商用和正当使用。
下载体验